

BI et médecine prédictive : les enjeux éthiques

De la médecine curative à la médecine prédictive, les données, le nouvel “or noir” de notre siècle, sont au cœur de la mutation digitale du secteur de la santé.
Autant que les données dans leur forme brute, fragmentées ou aléatoirement collectées, n’auraient du sens que lorsqu’elles sont minutieusement nettoyées, analysées, visualisées et efficacement exploitées, la BI ou l’informatique décisionnelle, avec ses outils d’analyse et de « reporting », pourrait apporter une solution optimale dans le processus de la prise de décision dans de nombreux domaines, y compris la médecine.
BI : apports et applications
Définie par Oracle, un leader du marché BI, comme “un processus technologique d’analyse des données et de présentation d’informations pour aider les dirigeants, managers et autres utilisateurs finaux de l’entreprise à prendre des décisions business éclairées”, les organisations de soins de santé ont recours aux systèmes d’aide à la décision médicale (SADM) dans le cadre de ce qu’on appelle la “business intelligence clinique” ou la “BI des soins de santé” afin d’obtenir des informations pertinentes au service de la qualité des soins offerte aux patients.
Sachant que selon l’enquête publiée par « Dimensional Insight » en 2017, plus que la moitié des organisations de santé n’ont pas mis en place un plan global de gouvernance des données malgré un volume colossal de data généré soit par les dossiers médicaux électroniques (DME), soit par les objets connectés, ou par le feedback des patients, une part importante des données brutes reste par conséquent inexploitée, d’où la grande importance accordée aujourd’hui aux outils avancés de biostatistiques adaptées aux besoins spécifiques du secteur.
Les technologies innovantes permettant l’analyse et l’accès instantané aux données, en offrant la possibilité de suivre les indicateurs clés de performance (key performance indicators, KPI) directement liés aux résultats des soins.
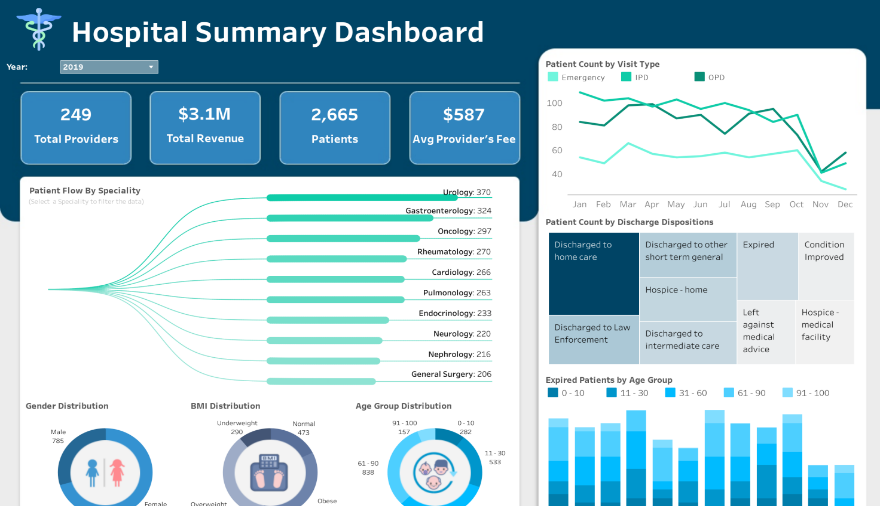
Dans la mesure où les données séparément conservées pourraient être intégrées dans des plateformes en ligne dont l’interface serait facilement accessible, après avoir été centralisées dans des entrepôts ou des « datawarehouses » dédiés au stockage sécurisé des données multi-sources, l’avantage finalement serait d’avoir une vue globale des antécédents des patients, facilitant généralement la détection des corrélations ou des « patterns » recherchés.
La BI, à travers le processus d’intégration de données appelé ELT (Extract, Load, Transform) et les techniques de visualisation de données (Dataviz) centralisées dans des tableaux de bords interactifs, pourrait, dans ce sens, être la réponse au problème de la fragmentation de l’information médicale qui a toujours caractérisé les systèmes de santé archaïques.
Dans la même optique, grâce aux avancées miraculeuses de la génomique depuis le projet international « Human Genome Project » en 2003, et les découvertes révolutionnaires de la transcriptomique (science des ARN messagers transcrits) et l’épigénétique, l’étude du génome facilite la détection et le diagnostic personnalisé des maladies avec une précision sans précédent. Les avancées scientifiques des sciences du vivant ont pour corollaire le boom de données susceptible de créer pour chacun une sorte de “Phénotypage numérique”.
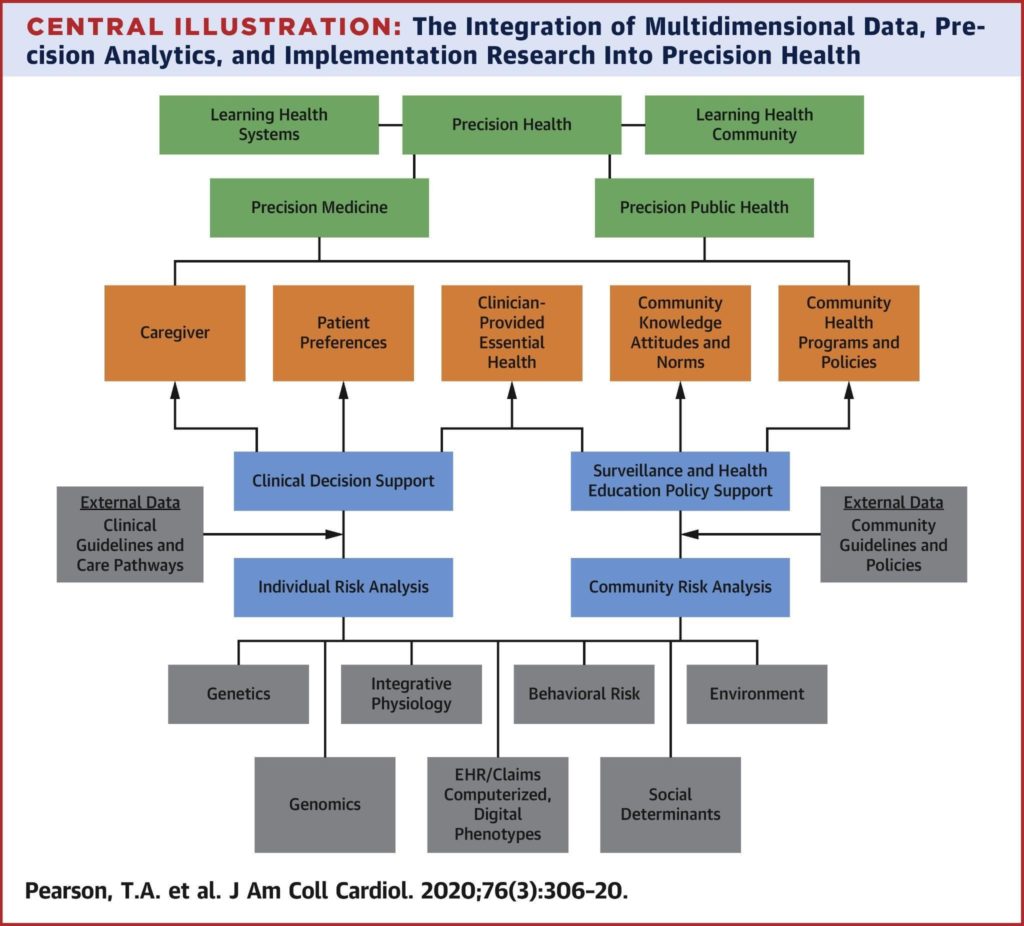
ESSOR DE LA MÉDECINE PRÉDICTIVE ET BIG DATA
Loin de la vision conventionnelle de l’intervention médicale, un changement du paradigme vient marquer la transition d’une médecine curative vers une médecine préventive, et ce grâce à la donnée, qui s’inscrit dans le mouvement de la « médecine 4P » (personnalisée, préventive, prédictive et participative).
De la réaction à l’anticipation, les applications cliniques de la médecine dite de précision, facilitées par les progrès technologiques considérables de l’intelligence artificielle, sont diverses : diagnostics précoces, identification aux biomarqueurs génétiques des maladies chroniques, et traitements préventifs.
A titre d’exemple, des chercheurs américains, dans le « Predictive Analytics and Comparative Effectiveness Center », ont développé un modèle statistique qui promet la détection précoce du diabète, un enjeu majeur de santé publique, en utilisant les données collectées auprès de 3000 personnes. L’objectif final est de donner des recommandations de santé en fonction du pourcentage de risque de développer du diabète déjà déterminé.
Predictive analytics : Dérives éthiques
La promesse d’une détection précoce présymptomatique des prédispositions à certaines maladies neurologiques (comme la maladie de Huntington), neuromusculaires (comme la myatonie de Steinert, la myopathie facio-scapulo-humérale), ou cardio-vasculaires (comme les cardiomyopathies hypertrophiques ou dilatées), et d’une prise en charge anticipatrice renforcée par le potentiel du « predictive analytics », n’est pas sans poser de nombreuses questions éthiques en rapport avec “le droit à l’oubli”, “le droit de ne pas savoir”, la médicalisation de l’expérience humaine, l’inégalité sociale au niveau de l’accès à son patrimoine génétique, et les dérives éthiques, voire eugénistes.
L’analyse et la modélisation prédictive qui reposent préalablement sur le data mining (fouille de données) est un processus confronté aux enjeux de la Big Data dans ses 5V (Volume, Variété, Vélocité, Véracité et Value) dès la phase de la conception d’un modèle prédictif.
Outre le cyber-risque, les biais algorithmiques inhérentes aux modèles de « machine learning » déployés, la logique data-driven de la médecine prédictive pousse à s’interroger en toute légitimité sur la manière dont on conserve et on gère des données aussi sensibles.
En effet, le consentement illusoire des patients qui n’en sont pas forcément conscients, la menace de la vie privée, la manipulation probable par les monopoles et les mutuelles santé, sont des enjeux de taille dans l’adoption de l’analytique.
De plus, au-delà des « dashboards » visuellement attractifs, une sorte de “dictature algorithmique” pourrait orienter les pratiques d’analyse de données et risque éventuellement de réduire l’être humain à sa dimension physique et médicale.
La personnalisation promise par la médecine prédictive ne serait-t-elle pas dans ce sens une forme déguisée de « dépersonnalisation » qui limite notre perception de l’homme à ce que les données nous révèlent ?
Au croisement de la biologique et de l’informatique décisionnelle, une approche biopsychosociale s’impose ainsi pour humaniser la pratique médicale et préserver la notion de la complexité unique de chaque individu dans le cadre d’une médecine « personnaliste » centrée sur l’humain.
A cela s’ajoute le fait que la méthodologie scientifique expérimentale appliquée depuis Claude Bernard (1) se voit également bouleversée, au lieu de générer les données à partir d’une expérimentation soumise à des protocoles bien définis et une hypothèse préalable, on valorise désormais des données déjà collectées initialement à partir d’autres sources et en vue d’autres besoins.
Dans une époque marquée par l’idéologie de la quantification et l’obsession transhumaniste d’un homme invincible, augmenté, et dont la santé est toujours prédictible, le big data Analytics et la BI doivent être réglementées au sens moral et juridique du terme, dans le cadre d’une approche éthico-technique potentiellement libératrice, holistique et humanisée valorisant le jugement humain loin de toute vision réductionniste.
Ecrit par : Youssef Zaatour
(1) : Né le 12 juillet 1813 à Saint-Julien et mort le 10 février 1878 à Paris, Claude Bernard est un médecin, physiologiste et épistémologue français. Considéré comme le fondateur de la médecine expérimentale, il a en particulier laissé son nom au syndrome de Claude Bernard-Horner. (Source : Wikipédia)













